
4n6ir.com
Windows Prefetch: Tech Details of New Research in Section A & B
by James Habben
I wrote previously with an overview about the research into Windows prefetch that I have been working on for years. This post will be getting more into the technical details of what I know to help others take the baton and get us all a better understanding of these files and the windows prefetch system.
I will be using my fork of the Windows-Prefetch-Parser to display the outputs in parsing this data. Some of the trace files I use below are public, but I didn’t have certain characteristics in my generated sample files to show all the scenarios.
https://github.com/JamesHabben/Windows-Prefetch-Parser
Section A Records
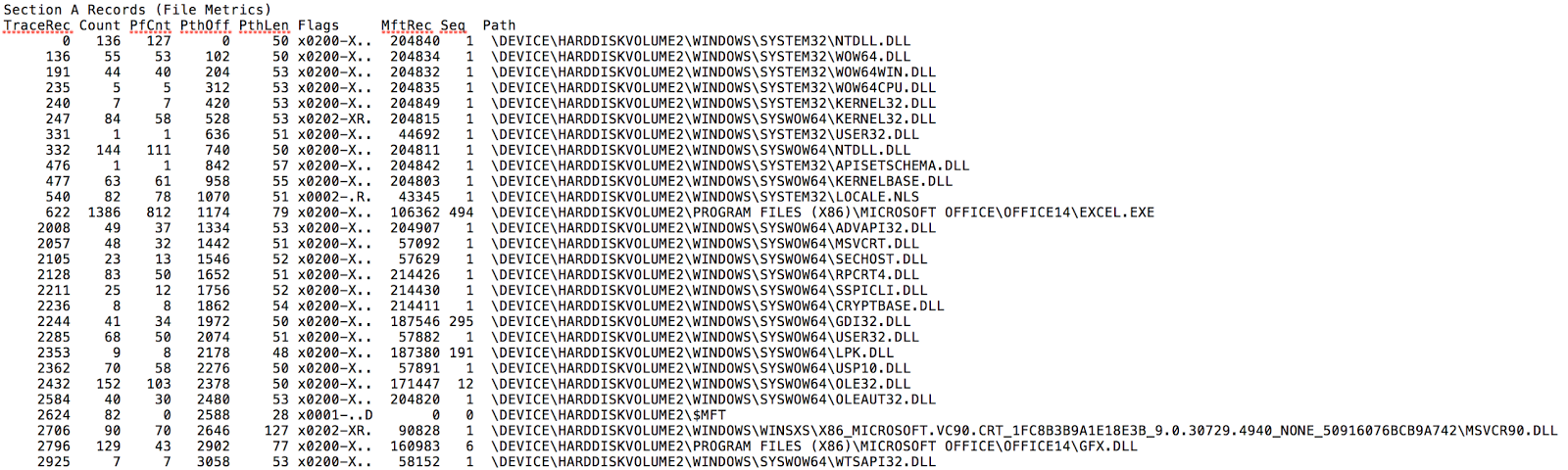
I will just start off with a table of properties for the section A records, referred to as the file metrics. The records are different sizes depending on the version. I have been working with the newer version (winVista+) and it has just a tad more info than the xp version.
Section A Version 17 format (4 byte records)
- 0 - trace chain starting index id
- 4 - total count of trace chains in section B
- 8 - offset in section C to filename
- 12 - number of characters in section C string
- 16 - flags
Section A Version 23 format (4 byte records, except noted)
- 0 - trace chain starting index id
- 4 - total count of trace chains in section B
- 8 - count of blocks that should be prefetched
- 12 - offset in section C to filename
- 16 - number of characters in section C string
- 20 - flags
- 24 (6) - $MFT record id</td>
- 30 (2) - $MFT record sequence update
As you can see between the tables, the records grew a bit starting with winVista to include a bit more data. The biggest difference is in the $MFT record references. Very handy to know the record number and the sequence update to be able to track down previous instances of files in $Log or $UsnJrnl records. The other added field is a count of blocks to be prefetched. There is a flag setting in the trace chain records that allows the program to specify if a block (or group) should be pulled fresh every time, somewhat like a web browser.
The flag values seem to be consistent between the two versions of files. This is an area that applies a general setting to all of the blocks (section B) loaded from the referenced file, but I have seen times where the blocks in section B were assigned a different flag value. Mostly, they line up. Here are the flag values
Flag values (integer bytes have been flipped from disk)
- 0x0200 X blocks (section B) will be loaded into executable memory sections
- 0x0002 R blocks (section B) will be loaded as resources, non-executable
- 0x0001 D blocks should not be prefetched
You can see these properties and the associated filenames in the output below. You will notice that the $MFT has been marked as one that shouldn’t be prefetched, which makes a lot of sense to not have stale data there. The other thing is that there are a couple DLL files that are referenced with XR because they are being requested to provide both executable code and non-executable resources.
Section B Records
This section has records that are much smaller, but there is so much more going on. The most exciting part to me is the bitfields that show a record of usage over the last eight program runs. You have probably seen these bitfields printed next to the file resource list of the python output when running the tool, but that data is not associated with either the filename in section C or the file metrics records in section A. These bitfields are actually tracking each of the block clusters in section B, so the output is actually a calculated value combined from all associated section B records. I will get to that later. Let’s build that property offset table first. These records have stayed the same over all versions of prefetch so far.
Section B record format
- 0 (4) - next trace record number (-1 if last block in chain)
- 4 (4) - memory block offset
- 8 (1) - Flags1
- 9 (1) - Flags2
- 10 (1) - usage bitfield
- 11 (1) - prefetched bitfield
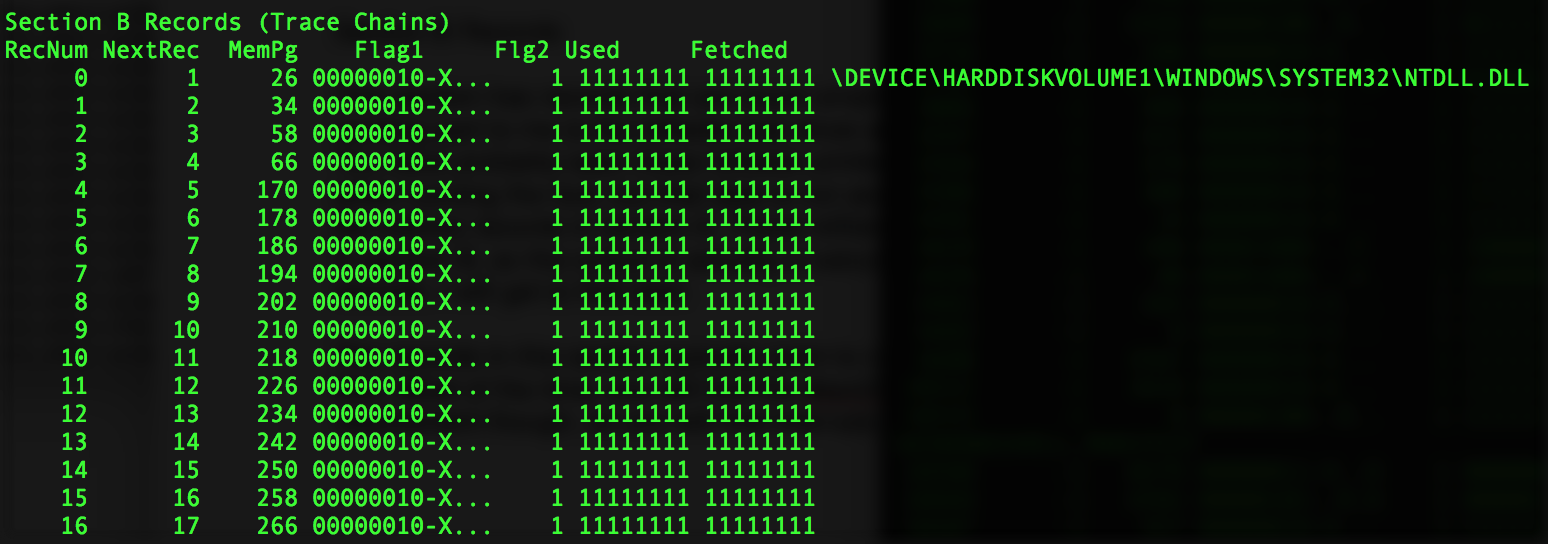
The records in this section typically point to clusters of 8 512 blocks that are loaded from the file on disk. Most of the time, you will find the block offset property walking up in values of 8. It isn’t a requirement though, so you will find intervals smaller than that as well.
Here is an example of these records walking by 8.
Here is an example of one record jumping in after 2.

Here is an example of a couple sequential records, jumping only by 1.

I broke the two flag fields up early on just to be able to determine what was going on with each of them. What I found out was that Flags2 is always a value of 1. I haven’t seen this change ever. Without a change, it is very difficult to determine the meaning of this value and field. I have kept it separate still because of the no change.
The Flags1 field is similar to the Flags field that is found in the section A records. It holds values for the same purposes (XRD), though the number values representing those properties aren’t necessarily the same. It also has a property that forces a block cluster to be prefetched as long as it has been used at least once in the last eight runs. I will get into more later about the patterns of prefetching that I have observed, but for now let’s build the table for the properties and their values.
- 0x02 X blocks are loaded as executable
- 0x04 R blocks are loaded as resources
- 0x08 F blocks are forced to be prefetched
- 0x01 D blocks will not be prefetched
Now I get to show my favorite part: the bitfields for usage and prefetch. They are each single byte values that hold eight slots in the form of bits. Every time the parent program executes, the bits are all shifted to the left. If this block cluster is used or fetched, the right most bit gets a 1; otherwise it remains 0. When a block cluster usage bitfield ends up with all 0, that block record is removed and the chain is resettled without it.
Imagine yourself sitting in front of a scrabble tile holder. It is has the capacity to hold only eight tiles, and it is currently filled with all 0 tiles. Each time the program runs and that block cluster is used, you put a 1 tile on from the right side. If the program runs and the block cluster is not used, then you place a 0 tile. Either way, you are going to push a tile off the left side because it doesn’t have enough room to hold that ninth tile. That tile is now gone and forgotten.
Prefetch Patterns
The patterns listed below occur in section B since this is where the two bitfields are housed. Remember that these are for block clusters and not for entire files. Here are some various scenarios around the patterns that I have seen. The assumption is neither the D or F property assigned unless specified. Also, none of these are guaranteed, just that I have observed them and noted the pattern at some point.
Block with the F (force prefetch) property assigned, after 1 use on 8th run:
- 10000000 11111111
Block with the D (don’t prefetch) property assigned, after a few uses:
- 01001011 00000000
Block that is generally used, but missed on one:
- 11011111 11111111
Block on first use:
- 00000001 00000000
Block on second run, single use:
- 00000010 00000001
Block on third run, single use:
- 00000100 00000011
Block on fourth run, single use:
- 00001000 00000110
Block used every other run:
- 01010101 00111111
Block used multiple times, then not:
- 01110000 00111111
Block used multiple times, but only one use showing:
- 10000000 11100000
More Work
I am excited to see what else can be learned about these files. My hope is that some of you take this data to test it and break it. You don’t have to be the best DFIR person out there to do that. All you need is that drive to learn.
James Habben
tags: Prefetch