
4n6ir.com
Connecting Jupyter Notebook to Amazon Security Lake data
by John Lukach
Initially, the project started as Python cloud configuration, data collection, and threat detection scripts lacking analysis capabilities.
Who needs another Cloud Security Posture Management (CSPM) in a crowded market with all the open source and vendor offerings?
Foolishly, I thought I did back in October 2022, as instead of waiting for updated parsers, the collection used the botocore data structures.
https://github.com/boto/botocore/tree/develop/botocore/data
It worked well to keep up with the AWS re:Invent releases until I ran out of steam in January 2023. In July 2023, I still required the capabilities, so I took the project in a new direction to make it more sustainable.
Enter Jupyter Notebook that runs anywhere from Amazon SageMaker, GitHub Codespaces, or wherever I have the most system resources available to provide the user interface to focus on threat hunting.
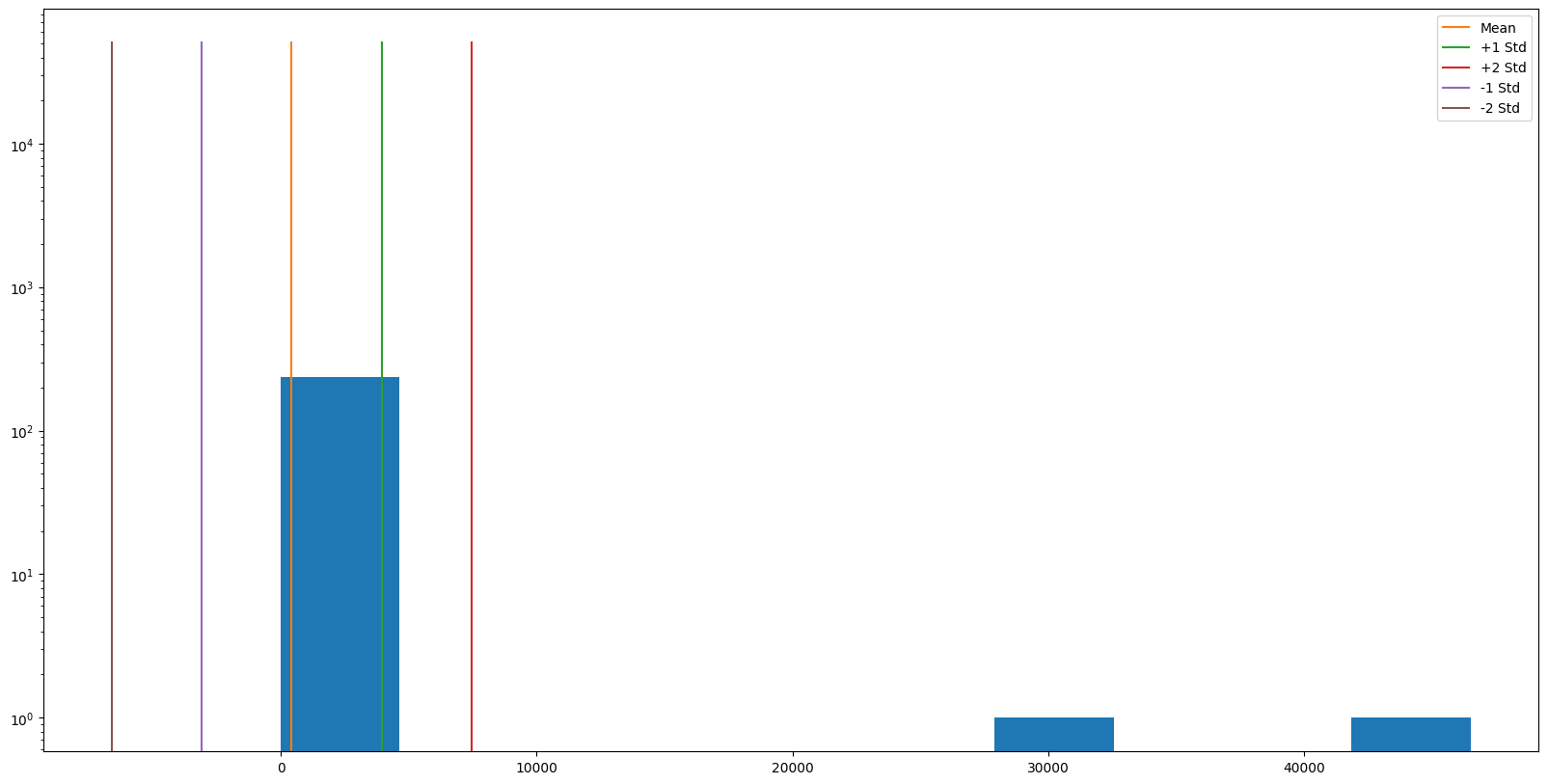
Amazon Route53 Resolver Queries
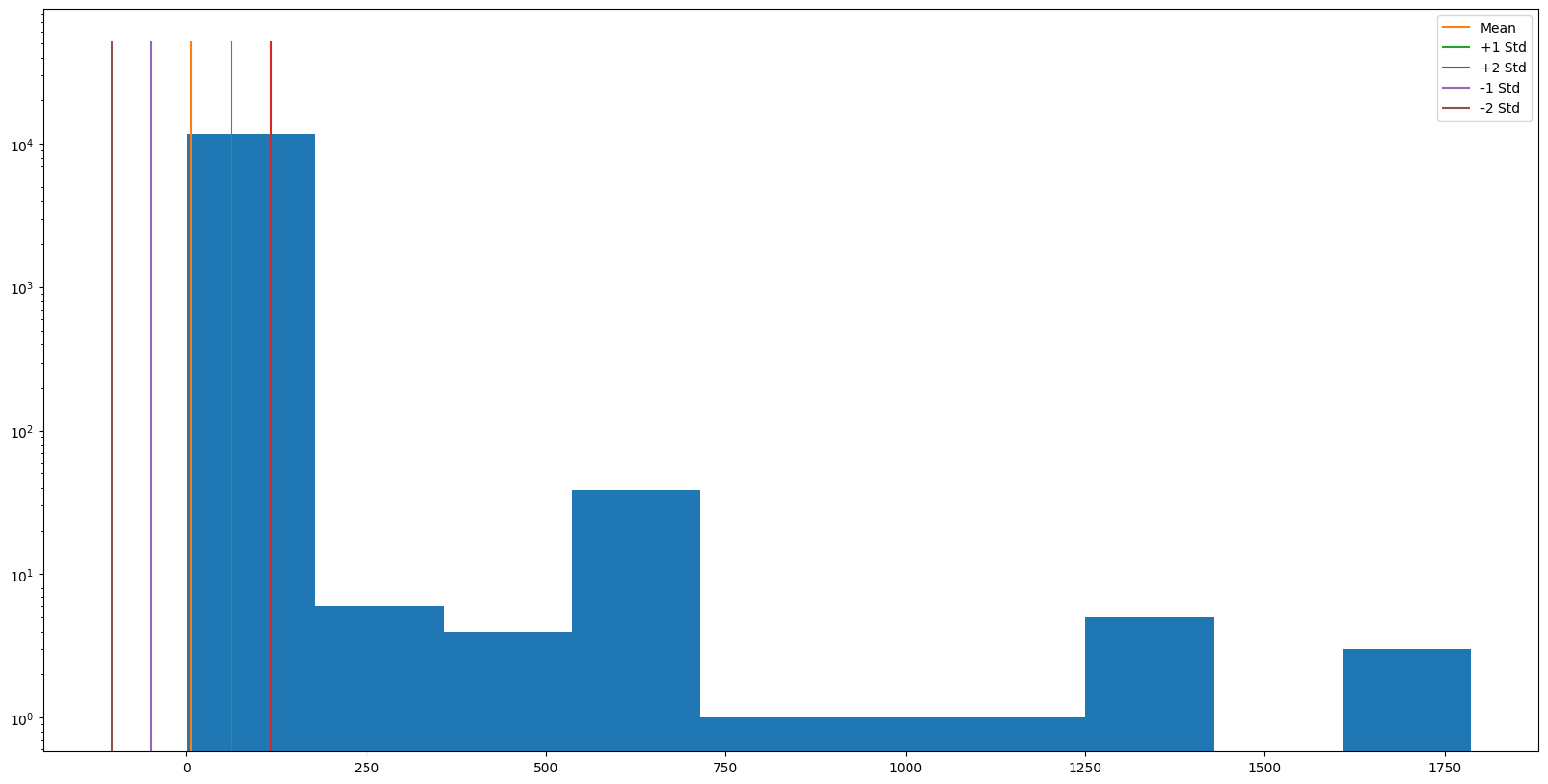
Amazon Route53 Resolver Answers
I changed the Python library to simplify authentication, collaboration, configuration, dependencies, and Amazon Security Lake data searching using Jupyter Notebook for analysis.
https://github.com/botoplus/botoplus
I will walk through the botoplus notebook in the GitHub repository. If you don’t have permission to access all the calls, the required information can be hard-coded into the notebook.
Authentication from your Jupyter Notebook will require the installation of AWS Command Line Interface (AWS CLI) Version 2 that supports AWS IAM Identity Center, previously called Single Sign-On (SSO).
import os
os.system('curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "../awscliv2.zip"')
os.system('unzip -o ../awscliv2.zip -d ../')
os.system('cd .. && sudo ./aws/install --update')
os.system('aws --version')
I will also install the aqueduct-utility for the botoplus Python library, which will help simplify the device authentication.
https://github.com/jblukach/aqueduct
import sys
!{sys.executable} -m pip install botoplus --upgrade
!{sys.executable} -m pip install aqueduct-utility --upgrade
I can log in to my organization by providing the Identity Store, SSO Region, SSO Role, CLI Region, and CLI Output.
import aqueduct.identity as _idp
_idp.login()
Amazon Security Lake requires the service to have administration delegated to another account. I can find the installation location by querying the organization’s management account or another delegated administration account.
import botoplus.botoplus as botoplus
selected_account = 'Unavailable'
session = botoplus.default()
client = session.client('organizations')
paginator = client.get_paginator('list_delegated_administrators')
pages = paginator.paginate()
for page in pages:
for item in page['DelegatedAdministrators']:
paginator2 = client.get_paginator('list_delegated_services_for_account')
pages2 = paginator2.paginate(
AccountId = item['Id']
)
for page2 in pages2:
for item2 in page2['DelegatedServices']:
if item2['ServicePrincipal'] == 'securitylake.amazonaws.com':
selected_account = item['Name']
print('Amazon Security Lake Delegated Administrator: '+selected_account)
I need to check what and where data ingestion occurs for the environment.
import botoplus.botoplus as botoplus
ingestion = []
try:
session = botoplus.defaults(selected_account)
securitylake = session.client('securitylake')
regions = securitylake.get_data_lake_organization_configuration()
for region in regions['autoEnableNewAccount']:
print(region['region'])
ingestion.append(region['region'])
for source in region['sources']:
print(' * '+source['sourceVersion']+' '+source['sourceName'])
except:
print('Amazon Security Lake Delegated Administrator: Unidentified')
pass
I also need to see the configuration for data replication to a central region.
import botoplus.botoplus as botoplus
replication = []
try:
session = botoplus.defaults(selected_account)
securitylake = session.client('securitylake')
lakes = securitylake.list_data_lakes(
regions = ingestion
)
for lake in lakes['dataLakes']:
try:
for region in lake['replicationConfiguration']['regions']:
replication.append(region)
except:
pass
except:
print('Amazon Security Ingestion Region(s): Unidentified')
pass
try:
replication = list(set(replication))
replication = replication[0]
print('Amazon Security Lake Replication Region: '+str(replication))
except:
pass
It is also good to verify the configured data retention.
import json
import botoplus.botoplus as botoplus
try:
session = botoplus.defaults(selected_account)
securitylake = session.client('securitylake')
lakes = securitylake.list_data_lakes(
regions = ingestion
)
for lake in lakes['dataLakes']:
if lake['region'] == replication:
print(json.dumps(lake['lifecycleConfiguration'], indent=4, sort_keys=True))
except:
print('Amazon Security Ingestion Region(s): Unidentified')
pass
We are all set to run our first search against the Amazon Route53 resolver query logs.
import botoplus.botoplus as botoplus
query = """
SELECT time,
metadata.product.version,
metadata.product.name AS service,
metadata.product.feature.name,
metadata.product.vendor_name,
metadata.profiles,
metadata.version AS securitylake,
src_endpoint.vpc_uid AS src_vpc_uid,
src_endpoint.ip AS src_ip,
src_endpoint.port AS src_port,
src_endpoint.instance_uid AS src_instance_uid,
query.hostname AS query_hostname,
query.type AS query_type,
query.class AS query_class,
connection_info.protocol_name,
connection_info.direction,
connection_info.direction_id,
dst_endpoint.instance_uid AS dst_instance_uid,
dst_endpoint.interface_uid AS dst_inaterface_uid,
severity_id,
severity,
class_name,
class_uid,
disposition,
disposition_id,
rcode_id,
rcode,
activity_id,
activity_name,
type_name,
type_uid,
unmapped,
region,
accountid,
eventday,
answers
FROM amazon_security_lake_glue_db_us_east_2.amazon_security_lake_table_us_east_2_route53_1_0
WHERE eventDay BETWEEN cast(
date_format(current_timestamp - INTERVAL '7' day, '%Y%m%d%H') as varchar
)
and cast(
date_format(current_timestamp - INTERVAL '0' day, '%Y%m%d%H') as varchar
)
ORDER BY time DESC
"""
converted = botoplus.convert(selected_account)
session = botoplus.defaults(selected_account)
athena = session.client('athena', region_name=replication)
athena.start_query_execution(
QueryString = query,
ResultConfiguration = {
'OutputLocation': 's3://temp-athena-results-'+converted['awsaccount']+'-'+replication+'/'
}
)
Better check if the search was successful and how big the data set returned.
import botoplus.botoplus as botoplus
query_execution_id = botoplus.execution()
try:
session = botoplus.defaults(selected_account)
athena = session.client('athena', region_name=replication)
output = athena.get_query_runtime_statistics(
QueryExecutionId = query_execution_id
)
print(' * Megabytes: '+str(output['QueryRuntimeStatistics']['OutputStage']['OutputBytes']/1000000))
print(' * Output Rows: '+str(output['QueryRuntimeStatistics']['OutputStage']['OutputRows']))
except:
print('Amazon Security Ingestion Region(s): Unidentified')
pass
Now, I can pull the data set over to my Jupyter Notebook for analysis.
import botoplus.botoplus as botoplus
import pandas as pd
session = botoplus.defaults(selected_account)
athena = session.client('athena', region_name=replication)
output = athena.get_query_execution(
QueryExecutionId = query_execution_id
)
bucket = output['QueryExecution']['ResultConfiguration']['OutputLocation']
out = bucket[5:].split('/')
print(bucket)
s3 = session.resource('s3')
s3.Object(out[0], out[1]).download_file('/tmp/'+out[1])
df = pd.read_csv('/tmp/'+out[1], sep=',')
pd.set_option('display.max_columns', None)
pd.set_option('display.max_rows', None)
df.head(1)